 FEDER
FEDER



¿Qué es la computación en el borde o perimetral?
Es una arquitectura distribuida de información en la que los datos del cliente se procesan en la periferia de la red, tan cerca de la fuente como sea posible. Actualmente aumenta rápidamente su aplicación en las empresas, en especial en los procesos de fabricación.
Los datos son la ‘sangre’ de las empresas, ya que sirven para respaldar la toma de decisiones. A medida que las empresas avanzan en la digitalización de sus procesos de negocio, sobre aquellas con fabricación, aumenta la necesidad de procesar cada vez más y más datos procedentes de sensores, PLCs, dispositivos IIoT, etc., que operan en tiempo real, en entornos operativos difíciles y en condiciones ambientales extremas y cambiantes.
El paradigma tradicional de datos centralizados e Internet comienza a no ser adecuado para procesar esa gran cantidad de datos en tiempo real debido a las limitaciones de ancho de banda, interrupciones impredecibles, latencias, etc. El número de dispositivos conectados a Internet, y el volumen de datos producidos por esos dispositivos y utilizados por las empresas, está creciendo demasiado rápido para que las infraestructuras de centros de datos se adapten. Finalmente, la aplicación de la AI a las máquinas, a la creación de gemelos digitales (fábrica virtual, Smart Factory), etc., acelerará el paso hacia la computación en el borde.
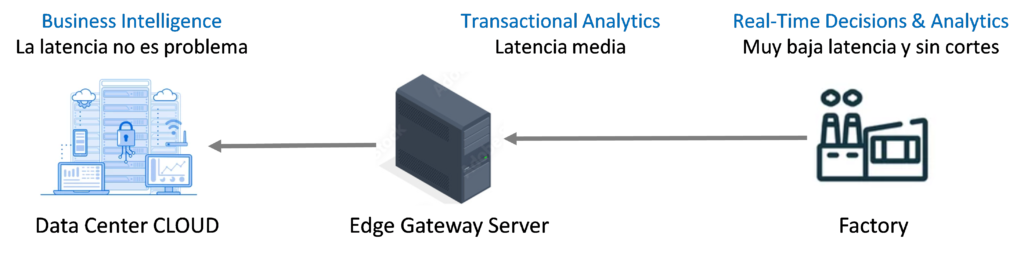
La computación en el borde traslada una porción de los datos almacenados y recursos de computación fuera de los datos centralizados acercándolos a la fuente de datos para que los operarios/máquinas/robots/control distribuido/etc., puedan actuar, tomar decisiones e interactuar en tiempo real con los procesos, planning, mantenimiento, calidad, recoger variables como temperaturas, humedades, settings de equipos, consumos energéticos, etc. Es muy simple, sino se pueden acercar las señales y datos de fábrica al data center, hay que llevar el data center a la fábrica. Sólo los resultados de la computación en el borde, se envían al data center, situado en la propia empresa o en la nube, para su revisión, evaluación, análisis históricos, toma de decisiones estratégicas, etc.
Ciberseguridad. ¿Es segura la computación en el borde?
Es evidente que las empresas continuarán descentralizando las operaciones de IT a entornos de nube híbrida durante el próximo año, y entre ellas estarán las industrias más estrictamente reguladas. Gartner predijo que para el 2025, más del 70% de los datos generados por la industria se crearán fuera de los centros de datos centralizados. Para hacerlo con éxito, las empresas deben tomar medidas de seguridad que garanticen la integridad del sistema y de los datos, e implementen estrategias de confianza. Actualmente ya existen tanto hardware como software para proteger la computación en el borde: LinuxONE, IBM-Z, cifrado Homomórfico (FHE), etc. Ver artículo ‘Z-TRUST’ en nuestro blog.
La arquitectura de datos de la fábrica del futuro será HÍBRIDA (MEC, Multi-access Edge Computing). Los departamentos de IT deben preparar la estrategia en la nube para poder entender la interacción entre la nube y la nube en el borde, y tienen que hacerlo para 5G, porque 5G jugará un papel muy importante a corto plazo. Para saber más, https://searchdatacenter.techtarget.com/